
五部门关于开展2024年新能源汽车下乡活动的通知
将偏置节点合并到您的神经网络中
来源:新能源汽车网
时间:2023-04-23 16:02:21
热度:
将偏置节点合并到您的神经网络中偏置节点可以添加到感知器的输入层或隐藏层,产生一个由设计者选择的常数值。我们在第 11 部分讨论了偏置值,如果您不清楚偏置节点是什么或它们如何修改并可
偏置节点可以添加到感知器的输入层或隐藏层,产生一个由设计者选择的常数值。
我们在第 11 部分讨论了偏置值,如果您不清楚偏置节点是什么或它们如何修改并可能增强神经网络的功能,我鼓励您阅读(或重新阅读)该文章的相关部分。
在这篇文章中,我将首先解释两种将偏置值合并到您的网络架构中的方法,然后我们将进行实验,看看偏置值是否可以提高我们在上一篇文章(第 16 部分)中获得的精度性能。
通过电子表格合并偏差
下图描绘了一个网络,该网络在输入层中有一个偏置节点,但在隐藏层中没有。

如果这是您正在寻找的配置,您可以使用包含训练或验证数据的电子表格添加偏差值。
这种方法的优点很简单,不需要大量的代码修改。步是在您的电子表格中插入一列并用您的偏差值填充它:

现在,您需要做的就是将输入层维度增加一个:

将偏见整合到代码中
如果您想要隐藏层中的偏置节点,或者如果您不喜欢使用电子表格,您将需要不同的解决方案。
假设我们要向输入层和隐藏层都添加一个偏置节点。首先,我们需要增加I_dim和H_dim,因为我们的目标是集成偏置节点,使它们像普通节点一样运行,但具有由设计人员选择且永远不会改变的预加权值。
我将按如下方式完成此操作:
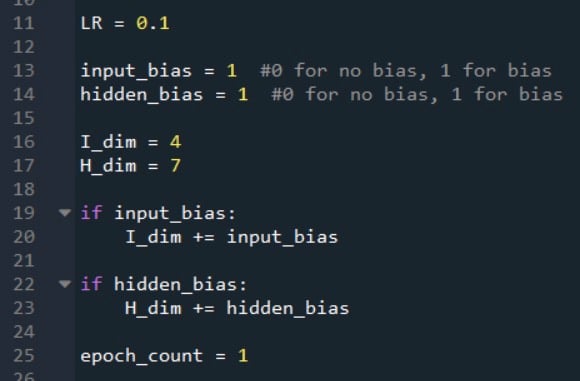
您可能还记得,我们使用以下代码组装训练数据集,分离目标输出值,并提取训练样本的数量。

在这些语句之后,二维数组training_data中的列数将等于电子表格中的输入列数。我们需要将列数增加一,以说明输入层中的偏置节点,同时我们可以用所需的偏置值填充此附加列。
下面的代码显示了如何做到这一点。
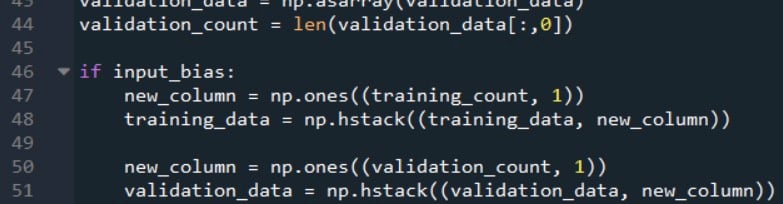
np.ones ()函数创建一个单列数组,其行数等于training_count,并将值 +1 分配给该数组中的每个元素。然后我们使用np.hstack()函数将单列数组添加到原始training_data数组的右侧。
请注意,我已对训练数据和验证数据执行了此过程。重要的是要记住,目标实际上并不是修改训练或验证数据;相反,我们正在修改数据作为实现所需网络配置的一种方式。
当我们查看感知器的框图时,偏置节点显示为网络本身的元素;因此,网络处理的任何样本都必须经过这种修改。
创建隐藏层偏置节点
我们可以通过修改计算隐藏层后激活值的 for 循环,然后手动插入一个隐藏节点(实际上是一个偏置节点)的偏置值,将偏置添加到前馈处理中。
次修改如下图:

如果网络配置为没有隐藏层偏置节点,则hidden_bias等于 0,for 循环的执行不变。
另一方面,如果我们决定包含一个隐藏层偏置节点,则 for 循环将不会计算层中终节点(即偏置节点)的激活后值。
下一步是增加节点变量,以便它访问postActivation_H数组中的偏置节点,然后分配偏置值。

请注意,这些修改也必须应用于代码的验证部分。
+1 以外的偏差值
根据我的经验,+1 是标准偏差值,我不知道是否有充分的理由使用其他数字。偏差由权重修改,因此选择 +1 不会严格限制偏差如何与网络的整体功能交互。
但是,如果您想尝试其他偏差值,则可以轻松实现。对于隐藏的偏差,您只需更改分配给postActivation_H[node]的数字。对于输入偏差,您可以将new_column数组(每个元素初都为 +1)乘以所需的偏差值。
测试偏差的影响
如果你读过第 16 部分,你就会知道我的感知器在对实验 3 中的样本进行分类时遇到了一些困难,这是“高复杂度”的问题。
让我们看看添加一个或多个偏置节点是否提供一致且显着的改进。
我的假设是分类准确度的差异相当微妙,因此对于这个实验,我平均运行 10 次而不是 5 次。训练和验证数据集是使用输入和输出之间相同的高复杂度关系生成的,隐藏层维度为 7。
以下是结果:

结论
如您所见,偏置节点并未导致分类性能发生任何显着变化。
这实际上并不让我吃惊——我认为偏置节点有时有点过分强调,并且考虑到我在这个实验中使用的输入数据的性质,我看不出偏置节点有什么帮助。
尽管如此,偏置在某些应用中是一项重要的技术;编写支持偏置节点功能的代码是个好主意,这样当您需要它时它就在那里。


-
确保电池供电的物联网传感器节点中的故障安全数据存储2023-03-02
-
「小电驴」江湖:谁在狂飙,谁在挨打?|节点深度2023-02-09
-
出行方式进化,滴滴D1成为一个历史节点!2021-01-06
-
汽车行业进入大变局的时间节点,中国新能源汽车如何换道超车?2020-12-23
-
新能源车竞争迎来变局 造车新势力面临存亡节点2019-06-13
-
清科资管:车主邦是我们在大出行市场的一个节点性布局2019-04-30
-
废旧动力电池开辟百亿市场 长线布局节点尚未降临2018-04-13
-
中机中心:明确时间节点 落实企业监测平台与国家新能源汽车监管平台对接2017-11-16
-
电动车替代燃油车是大势所趋 2025年将是节点2017-10-20
-
逐条解读新能源车双积分政策:目标和时间节点没变是亮点2017-06-21
-
无人驾驶推进时间表曝光 这些关键技术节点get到吗?2017-04-12
-
电动汽车份额亟待提升 2020年是关键节点2016-09-10
-
微型温差电池的无线传感器节点自供电系统设计2016-07-27
-
CAN总线下的燃料电池汽车空调控制节点2016-06-26
-
小型温差电池的无线传感器节点自供电系统设计2016-06-25